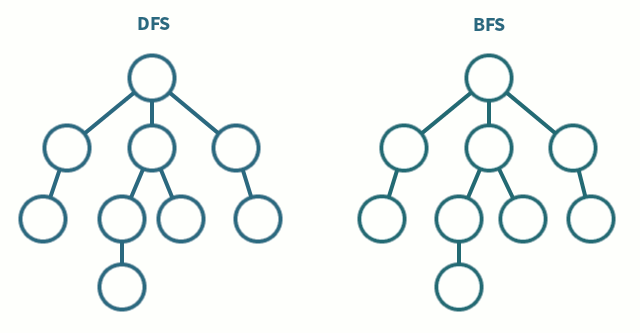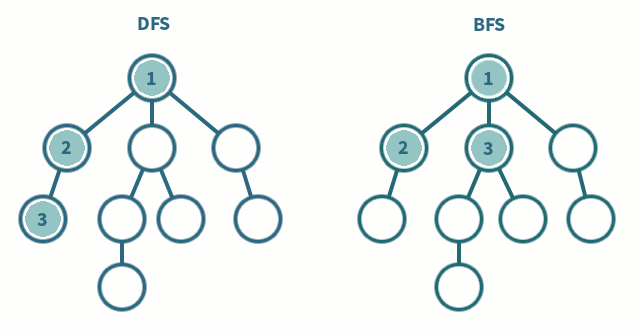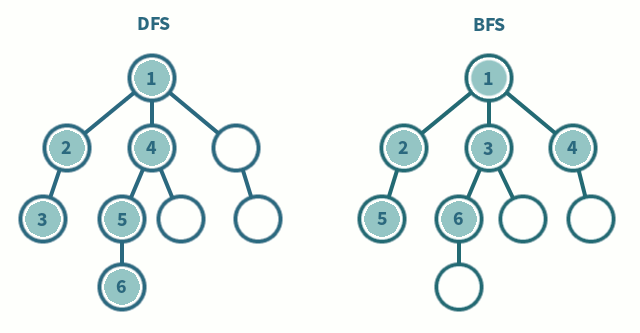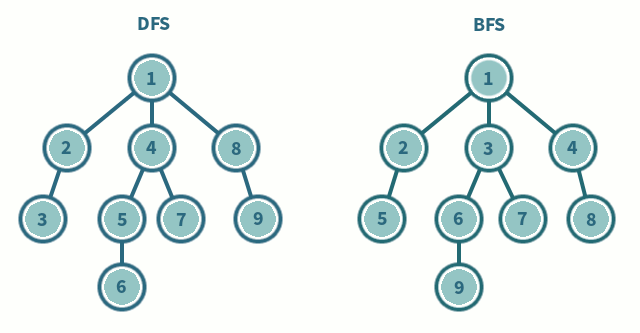
현재 학교 졸업 프로젝트로 강화 학습 관련 프로젝트를 진행하고 있다. 그러면서 DQN에 대한 차이를 설명하면서 여러 자료를 보게 됐고, 이를 좀 정리하기 위해 남겨 놓는다. Deep Q-Network Q-Learning에 Value Function Approximation(VFA)을 사용하는 것은, Weight Update 과정에서 샘플들 간의 상관관계와, Non-stationary Target으로 인해 수렴하지 않고 발산 가능성이 있다. 이러한 문제를 해결할 필요가 있는데 Deep Q-Learning(DQN)이 이 문제를 Experience Repaly와 Fixed Q-targets으로 해결을 시도하였다. State, Action을 Q-Table로 정의하기에 Table이 너무 방대해지는 경우(ex, 간..