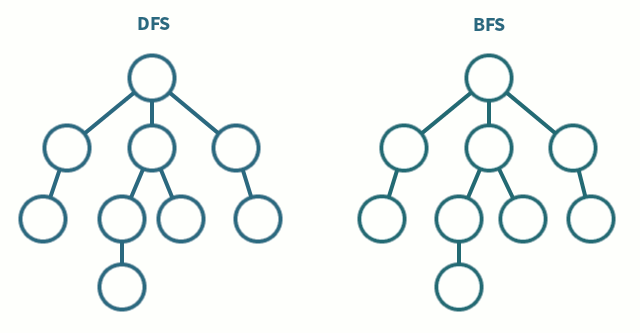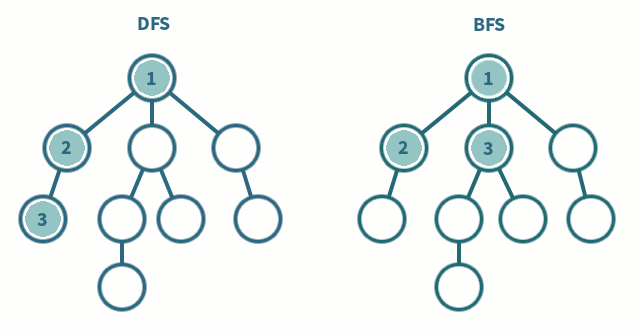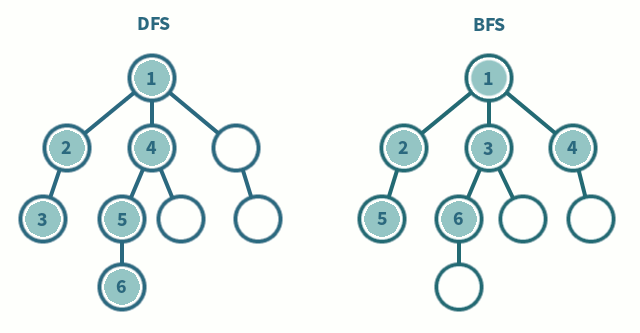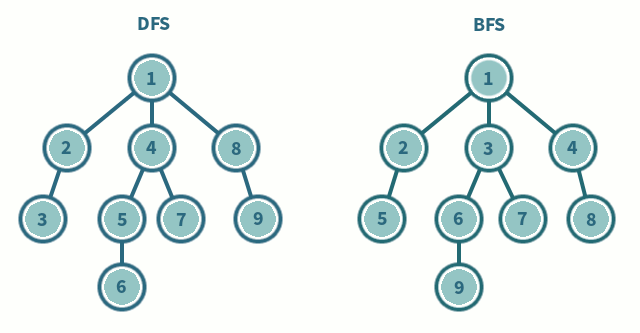
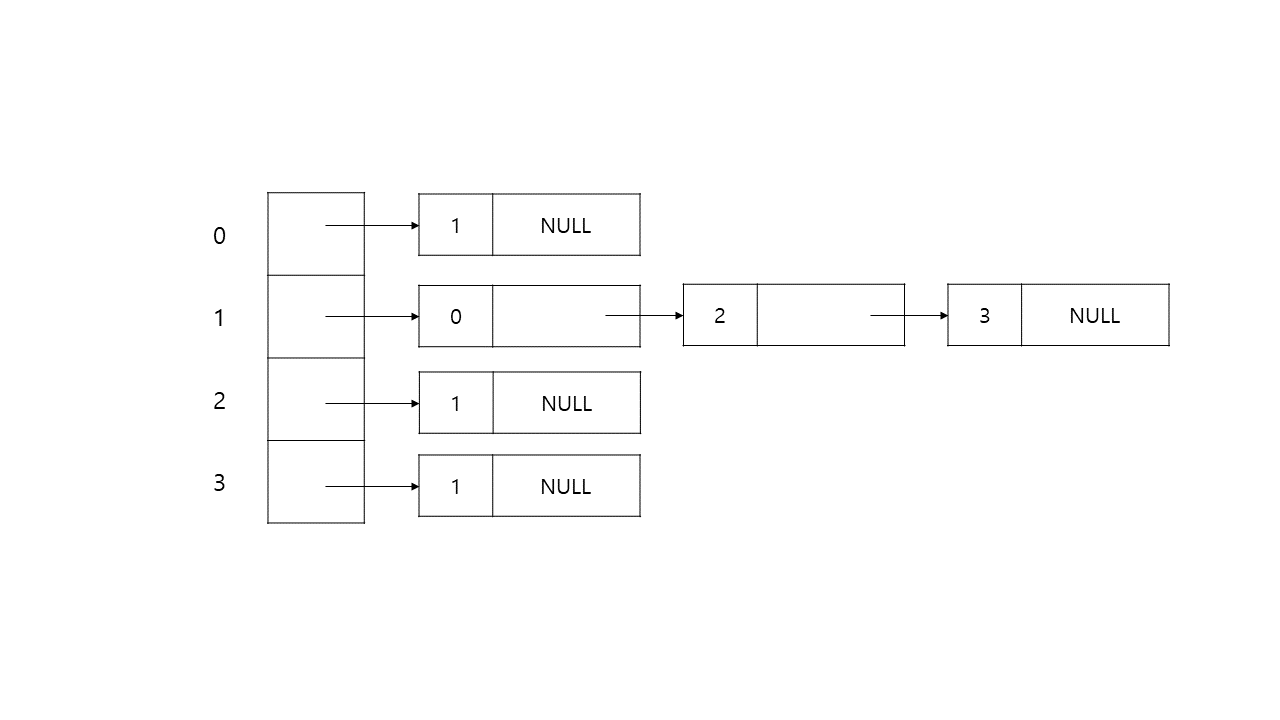
깊이 우선 탐색과 너비 우선 탐색에 대해 간단하게 비교하여 정리하고자 한다. 두 알고리즘은 생각보다 알고리즘 문제 풀이에서 많이 볼 수 있고, 각각의 응용 방식을 통해 나오는 코딩 테스트 문제가 많기 때문에 참고해두는 것이 좋고, 기본적인 구현 방식은 알고 접근하는 것이 좋다. 기본적인 구현 코드는 백준 온라인 저지의 1260번 DFS와 BFS 을 구현하는 코드이다. DFS(Depth-First Search) Stack으로 구현할 수 있고, 함수 호출도 Stack처럼 이뤄지기 때문에 대부분 재귀 함수로 구현된 코드들이 많다. DFS는 미로 찾기로 치면, 막히는 곳까지 계속 파고 드는 Leaf-wise한 방식이다. 분기점이 나오면 길 하나를 선택하고 더 이상 진행하지 못하는 시점까지 진행한다고 보면 이해하..