CNN을 활용해서 어떤 제품의 이미지를 보고 불량인지 정상품인지 분류하는 모델을 만들어봤다.
활용 데이터셋
원래의 데이터셋(NEU Surface Defect DB)은 크랙, 기름때, 스크래치 같은 다양한 종류의 열연강판에 대한 불량품들만 모아놓은 데이터셋이다. 여기서 멀쩡한 부분들만 잘라서 분류해놓은 데이터셋을 활용했다. 총 1344장의 이미지가 있고, 정상은 952장 불량은 392장으로 이루어져 있다. 클래스 비율에 맞춰 8:1:1 비율로 train, validation, test를 나눴다.
https://github.com/kazenokizi/defect_classification/blob/master/data.rar
모델 구현
케라스를 활용했는데, 직접 레이어를 쌓지 않고 VGG16의 Weight를 가져오고 마지막의 classification을 위해서 Fully-Connected Layer만 수정해주는 작업을 거쳤다. 최초에 활용하던 책에 있던 내용 그대로 코드를 적용시키면서 Learning Rate를 2e-5로, Optimizer를 RMSprop로 두고 학습을 진행했는데 train set accuracy가 validation set accuracy보다 낮게 나오는 경향을 보였다.


보통의 경우 train에 대한 accuracy가 validation에 대한 accuracy보다 높다. 그런데 validation이 더 높게 나오는 상황은 validation에 문제가 있는 것일 수 있다. 원인을 찾아봤다. Data Augmenatation 부분이 문제였다. 초기에 train에 대해서만 Data Augmentation을 다양하게 넣어줬는데, 이것이 train의 분류 난이도를 높여 validation 문제가 상대적으로 쉬워져서 발생한 문제였다.
validation set이 train set보다 복잡하지 않으면 이런 역전 현상이 발생하는데 Data Augmentation을 train set에 대해서만 Augmentation을 진행해서 발생한 문제였다. 그래서 이 문제를 수정하고 Data Augmentation을 두 데이터셋에 모두 적용해서 train, validation 결과를 보니 이상적인 결과가 나왔다. 이후에, Optimizer를 Adam으로 바꾸고, Learning Rate도 조금 변경해봤다.
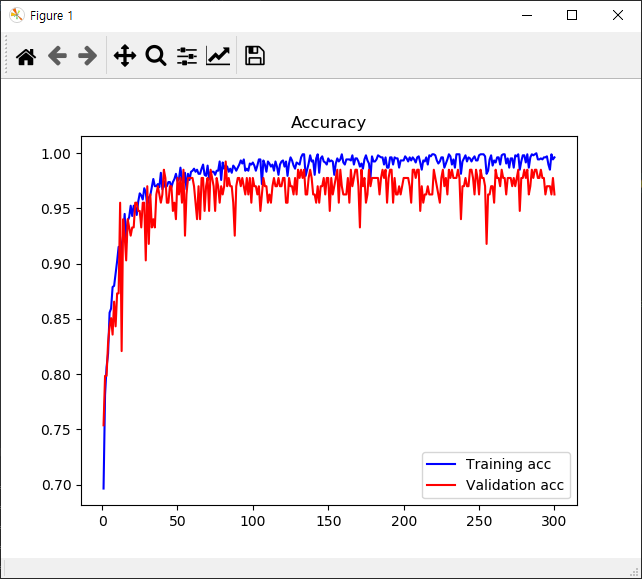

최종 결과
Test로 최종적으로 확인한 결과 100% 맞추는 가히 기적적인 결과가 나온다. validation loss가 지나치게 튀는 부분이나 이런 것들은 조금 더 파악을 해봐야 하겠지만, 일단 데이터 자체가 적은 편이었고

수행 결과물 Repository
https://github.com/Twinparadox/Defects-Detection
회고
지금까지 딥러닝이라고 하면 CNN이나 GAN이나 이런저런 프로젝트들을 github에서 끌어와서 돌려본 것들이 전부여서 이렇다 할 문제 해결 과정을 거쳐본 적이 없었다. 이번 과제를 수행하면서, 다양한 오류와 문제점들을 마주할 수 있어 매우 좋았다. 문제를 해결한 것도 있고, 이렇다 할 해결 방법 없이 회피한 것도 있어서 해결해야 할 과제들이 남아 있긴 하지만, 꽤나 의미 있는 과제였다.
Reference
Reference
Home - Keras Documentation
케라스는 파이썬으로 작성된 고수준 신경망 API로 TensorFlow, CNTK, 혹은 Theano와 함께 사용하실 수 있습니다. 빠른 실험에 특히 중점을 두고 있습니다. 아이디어를 결과물로 최대한 빠르게 구현하는 것은 훌륭한 연구의 핵심입니다. 케라스는 다음의 파이썬 버전과 호환됩니다: Python 2.7-3.6. 케라스의 주요 데이터 구조는 model,로 레이어를 조직하는 방식입니다. 가장 간단한 종류의 모델인 Sequential 모델은 레이어를 선형
keras.io
https://github.com/kazenokizi/defect_classification
kazenokizi/defect_classification
Defect classificaiton using NEU dataset. Contribute to kazenokizi/defect_classification development by creating an account on GitHub.
github.com
'Computer Science > DL, ML' 카테고리의 다른 글
| PyQt5 GUI로 딥러닝(Deep Learning) 모델을 동작시키는 간단한 예제 (3) | 2020.04.18 |
|---|---|
| 케라스(Keras)에서 모델 학습 중 loss가 nan으로 나오는 문제, 예측 값이 nan으로 나오는 문제 (1) | 2020.03.04 |
| 욜로(YOLO) Cannot load image, Couldn't open file, Segmentation fault 에러 해결 방법 (0) | 2020.02.19 |
| 머신러닝(Machine Learning) 관련한 프로젝트 아이디어와 관련 툴 (0) | 2019.11.28 |
| 텐서플로우(Tensorflow) 버전 확인하기 (0) | 2018.04.27 |